Git as a Database: Harnessing the Hidden Power of Internals for Chronological Data Storage
When we think of Git, the first association we make is with code version control. However, Git’s internal mechanisms are so well designed that they can be leveraged for purposes beyond traditional version control. A particularly interesting use is as a database, especially for data that benefits from historical and chronological tracking. In this post, we’ll explore Git’s internal structure and how it can be adapted to function as an efficient database.
Git’s Internal Structure
Git is fundamentally a content-addressable storage system. This means that Git’s central mechanism is a simple key-value store. You insert any type of content, and Git returns a unique key that can be used to retrieve that content at any time.
Git Objects
Git stores all its content in four main types of objects:
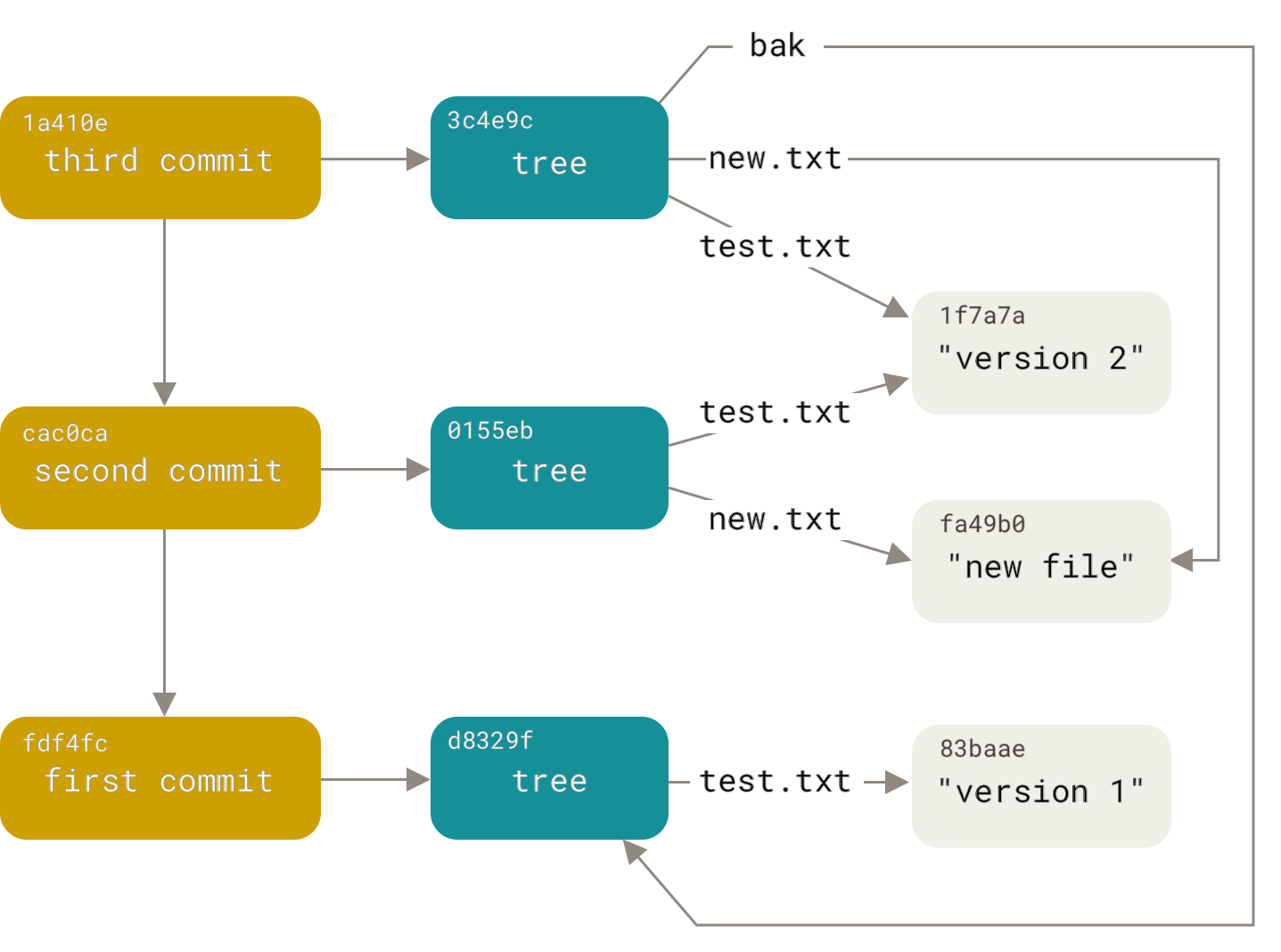
- Blobs: Store file contents without any metadata about the name or structure. A blob is treated by Git as a chunk of bytes. When you add a file to Git, it compresses the content, generates a header identifying the object type (blob) and content size, and calculates the SHA-1 hash of this combination. This hash becomes the unique identifier of the object in Git’s database.
- Trees: Represent directories and contain references to blobs and other trees. A tree solves the problem of storing filenames and allows storing groups of files. Technically, a tree in Git is an object that contains a list of entries, each with a mode, a type (blob or tree), a SHA-1 hash, and a filename. It’s analogous to a directory in a file system.
- Commits: Point to a specific tree (the state of the project at that moment) and contain metadata such as author, committer, message, and timestamps. A commit can also have one or more parent commits, thus creating the project’s timeline. Each commit represents a complete snapshot of the project, not just the differences.
- Tags: Point to specific commits with a friendly name, typically used to mark specific versions.
All these objects are stored in the .git/objects directory and are immutable. Once created, they cannot be changed without changing their SHA-1 identifier, which ensures data integrity.
Reference System and Index
Git maintains references (such as branches and tags) that point to specific commits. These references are simply files containing the SHA-1 hash of the corresponding commit, stored in .git/refs/.
The index (or staging area) is an intermediate area where changes are prepared before being committed. Technically, it’s a binary file (.git/index) that contains an ordered list of file paths with their modes and the SHA-1 hashes of the corresponding blobs, representing the next snapshot to be committed.
Plumbing and Porcelain
Git divides its commands into two categories:
- Plumbing: Low-level commands that directly manipulate objects and references
- Porcelain: High-level commands that users typically use (such as
git commit,git branch)
To use Git as a database, we often resort to plumbing commands to directly manipulate objects in the repository.
Concept Mapping: From Database to Git
To use Git as a database, we need to align traditional database concepts with Git elements:
Term alignment, from database to git The goal is to speak the same language as the database world
- database: git repository (local or remotely)
- scheme: git branch
- table: directory added on git repository
- field struct: json (document) - will be persisted in a file and indexed in lucene
This mapping allows us to think of Git in terms familiar to the database world:
- A Git repository functions as a database, where all objects are stored in
.git/objectsusing an efficient storage format - A branch represents a database schema, being just a reference to a specific commit
- A directory in the repository functions as a table, implemented internally as a tree object
- JSON files store documents (records) with their field structure, each file being stored as a blob
How Git Stores Data Internally
When we add a file to Git, several operations occur behind the scenes:
- The file content is compressed
- A header is added (containing type and size)
- A SHA-1 hash is calculated for this combination
- The object is stored in
.git/objects/xx/yyyyy..., where xx are the first two characters of the hash and yyyyy… is the remainder
For example, if we have a file with the content “hello world”, Git:
- Compresses the content
- Adds a header like “blob 11\0” (11 bytes of content)
- Calculates the SHA-1 hash of this set
- Stores the compressed object in the file system
This storage mechanism is extremely efficient for data that doesn’t change frequently, as is the case in many document databases.
Advantages of Git as a Database
1. Native Versioning
The main advantage is automatic versioning. Each data change is recorded with author, timestamp, and descriptive message. This provides a complete history of changes without the need for additional implementation.
2. Branch and Merge Operations
Git allows easy creation of branches, which enables:
- Testing changes in datasets without affecting the main data
- Working in parallel on different versions of the data
- Merging changes in a controlled manner
3. Distribution and Synchronization
As a distributed system, Git facilitates:
- Offline work with later synchronization
- Data replication between multiple nodes
- Structured conflict resolution
4. Integrated Auditing
Git’s history serves as a natural audit trail:
- Who changed which data
- When changes were made
- What the specific changes were
- Why changes were made (through commit messages)
5. Compression and Deduplication
Git stores objects efficiently:
- Automatically compresses content
- Deduplicates identical content (same content = same hash)
- Periodically packs objects into pack files for greater efficiency
Challenges and Considerations
Despite the advantages, there are challenges to using Git as a database:
- Performance: Git was not optimized for complex queries or high transaction frequency
- Scalability: Very large repositories may have performance issues
- Queries: There is no native query language like SQL
- Concurrency: Git’s concurrency model is based on merges, not locks or ACID transactions
ChronDB: A Git-Based Database
Fortunately, we don’t need to reinvent the wheel to leverage Git as a database. ChronDB (https://github.com/moclojer/chrondb) is a project that implements exactly this idea. Developed by the Moclojer team, ChronDB is a chronological key-value database that uses Git’s internal architecture as its storage engine.
Written in Clojure, ChronDB leverages the functional and immutable nature of the language to complement Git’s characteristics. The project offers a more user-friendly API for database operations, abstracting the complexity of the underlying Git commands.
ChronDB is currently in active development and represents a practical approach to using Git as a chronological database. The project demonstrates that the concepts discussed in this post are not just theoretical but can be efficiently implemented for real-world use cases.
If you’re interested in databases with strong versioning and chronological tracking capabilities, it’s worth checking out ChronDB and considering how this innovative approach can benefit your projects.
Conclusion
Git, with its robust and flexible architecture, offers a surprisingly suitable foundation for implementing a chronological database. While it doesn’t replace traditional databases for all use cases, it presents significant advantages for applications that benefit from complete versioning and change history.
ChronDB is turning this possibility into reality, offering a practical implementation of a Git-based database. As the project continues to evolve, we can expect to see more features and optimizations that make the most of Git’s potential as a data storage engine.


